Monte Carlo Simulation Construction Projects
This article covers the why, what and how of Monte Carlo simulation using a canonical example from project management – estimating the duration of a small project. Before starting, however, I'd like say a few words about the tool I'm going to use.
Despite the bad rap spreadsheets get from tech types – and I have to admit that many of their complaints are justified – the fact is, Excel remains one of the most ubiquitous "computational" tools in the corporate world. Most business professionals would have used it at one time or another. So, if you you're a project manager and want the rationale behind your estimates to be accessible to the widest possible audience, you are probably better off presenting them in Excel than in SPSS, SAS, Python, R or pretty much anything else. Consequently, the tool I'll use in this article is Microsoft Excel. For those who know about Monte Carlo and want to cut to the chase, here's the Excel workbook containing all the calculations detailed in later sections. However, if you're unfamiliar with the technique, you may want to have a read of the article before playing with the spreadsheet.
In keeping with the format of the tutorials on this blog, I've assumed very little prior knowledge about probability, let alone Monte Carlo simulation. Consequently, the article is verbose and the tone somewhat didactic.
Introduction
Estimation is key part of a project manager's role. The most frequent (and consequential) estimates they are asked deliver relate to time and cost. Often these are calculated and presented as point estimates: i.e. single numbers – as in, this task will take 3 days. Or, a little better, as two-point ranges – as in, this task will take between 2 and 5 days. Better still, many use a PERT-like approach wherein estimates are based on 3 points: best, most likely and worst case scenarios – as in, this task will take between 2 and 5 days, but it's most likely that we'll finish on day 3. We'll use three-point estimates as a starting point for Monte Carlo simulation, but first, some relevant background.
It is a truism, well borne out by experience, that it is easier to estimate small, simple tasks than large, complex ones. Indeed, this is why one of the early to-dos in a project is the construction of a work breakdown structure. However, a problem arises when one combines the estimates for individual elements into an overall estimate for a project or a phase thereof. It is that a straightforward addition of individual estimates or bounds will almost always lead to a grossly incorrect estimation of overall time or cost. The reason for this is simple: estimates are necessarily based on probabilities and probabilities do not combine additively. Monte Carlo simulation provides a principled and intuitive way to obtain probabilistic estimates at the level of an entire project based on estimates of the individual tasks that comprise it.
The problem
The best way to explain Monte Carlo is through a simple worked example. So, let's consider a 4 task project shown in Figure 1. In the project, the second task is dependent on the first, and third and fourth are dependent on the second but not on each other. The upshot of this is that the first two tasks have to be performed sequentially and the last two can be done at the same time, but can only be started after the second task is completed.
To summarise: the first two tasks must be done in series and the last two can be done in parallel.

Figure 1; A project with 4 tasks.
Figure 1 also shows the three point estimates for each task – that is the minimum, maximum and most likely completion times. For completeness I've listed them below:
- Task 1 – Min: 2 days; Most Likely: 4 days; Max: 8 days
- Task 2 – Min: 3 days; Most Likely: 5 days; Max: 10 days
- Task 3 – Min: 3 days; Most Likely: 6 days; Max: 9 days
- Task 4 – Min: 2 days; Most Likely: 4 days; Max: 7 days
OK, so that's the situation as it is given to us. The first step to developing an estimate is to formulate the problem in a way that it can be tackled using Monte Carlo simulation. This bring us to the important topic of the shape of uncertainty aka probability distributions.
The shape of uncertainty
Consider the data for Task 1. You have been told that it most often finishes on day 4. However, if things go well, it could take as little as 2 days; but if things go badly it could take as long as 8 days. Therefore, your range of possible finish times (outcomes) is between 2 to 8 days.
Clearly, each of these outcomes is not equally likely. The most likely outcome is that you will finish the task in 4 days (from what your team member has told you). Moreover, the likelihood of finishingin less than 2 days ormore than 8 days is zero. If we plot the likelihood of completion against completion time, it would look something like Figure 2.

Figure 2: Likelihood of finishing on day 2, day 4 and day 8.
Figure 2 begs a couple of questions:
- What are therelative likelihoods of completion for all intermediate times – i.e. those between 2 to 4 days and 4 to 8 days?
- How can onequantify the likelihood of intermediate times? In other words, how can one get anumerical value of the likelihood for all times between 2 to 8 days? Note that we know from the earlier discussion that this must be zero for any time less than 2 or greater than 8 days.
The two questions are actually related. As we shall soon see, once we know the relative likelihood of completion at all times (compared to the maximum), we can work out its numerical value.
Since we don't know anything about intermediate times (I'm assuming there is no other historical data available), the simplest thing to do is to assume that the likelihood increases linearly (as a straight line) from 2 to 4 days and decreases in the same way from 4 to 8 days as shown in Figure 3. This gives us the well-known triangular distribution.
Jargon Buster : The termdistribution is simply a fancy word for a plot of likelihood vs. time.

Figure 3: Triangular distribution fitted to points in Figure 1
Of course, this isn't the only possibility; there are an infinite number of others. Figure 4 is another (admittedly weird) example.

Figure 4: Another distribution that fits the points in Figure 2.
Further, it is quite possible that the upper limit (8 days) is not a hard one. It may be that in exceptional cases the task could take much longer (for example, if your team member calls in sick for two weeks) or even not be completed at all (for example, if she then leaves for that mythical greener pasture). Catering for the latter possibility, the shape of the likelihood might resemble Figure 5.

Figure 5: A distribution that allows for a very long (potentially) infinite completion time
The main takeaway from the above is that uncertainties should be expressed as shapes rather than numbers, a notion popularised by Sam Savage in his book, The Flaw of Averages.
[Aside: you may have noticed that all the distributions shown above are skewed to the right – that is they have a long tail. This is a general feature of distributions that describe time (or cost) of project tasks. It would take me too far afield to discuss why this is so, but if you're interested you may want to check out my post on the inherent uncertainty of project task estimates.
From likelihood to probability
Thus far, I have used the word "likelihood" without bothering to define it. It's time to make the notion more precise. I'll begin by asking the question: what common sense properties do we expect aquantitative measure of likelihood to have?
Consider the following:
- If an event is impossible, its likelihood should be zero.
- The sum of likelihoods of all possible events should equal complete certainty. That is, it should be a constant. As this constant can be anything, let usdefine it to be 1.
In terms of the example above, if we denote time by 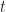
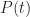
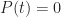
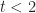
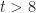
And
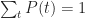
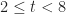
Where 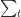
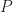

With these assumptions in hand, we can now obtain numerical values for the probability of completion for all times between 2 and 8 days. This can be figured out by noting that the area under the probability curve (the triangle in figure 3 and the weird shape in figure 4) must equal 1, and we'll do this next. Indeed, for the problem at hand, we'll assume that all four task durations can be fitted to triangular distributions. This is primarily to keep things simple. However, I should emphasise that you can use any shape so long as you can express it mathematically, and I'll say more about this towards the end of this article.
The triangular distribution
Let's look at the estimate for Task 1. We have three numbers corresponding to aminimum,most likelyandmaximumtime. To keep the discussion general, we'll call these 


Now, what about the probabilities associated with each of these times?
Since 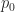

Figure 6: Triangular distribution redux.
For the simulation, we need to know the equation describing the above distribution. Although Wikipedia will tell us the answer in a mouse-click, it is instructive to figure it out for ourselves. First, note that the area under the triangle must be equal to 1 because the task must finish at some time between
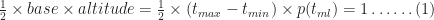
where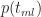
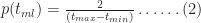
To derive the probability for any time
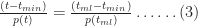
This is a consequence of the fact that the ratios on either side of equation (3) are equal to the slope of the line joining the points 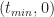
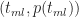

Figure 7
Substituting (2) in (3) and simplifying a bit, we obtain:
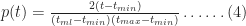
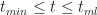
In a similar fashion one can show that the probability for times lying between
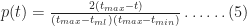

Equations 4 and 5 together describe the probability distribution function (or PDF) for all times between
As it turns out, in Monte Carlo simulations, we don't directly work with the probability distribution function. Instead we work with the cumulative distribution function (or CDF) which is the probability, 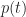

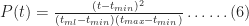
Noting that for 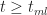
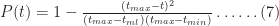
As expected,
To end this section let's plug in the numbers quoted by our estimator at the start of this section: 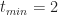
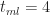
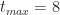

Figure 8: PDF for triangular distribution (tmin=2, tml=4, tmax=8)

Figure 9 – CDF for triangular distribution (tmin=2, tml=4, tmax=8)
Monte Carlo in a minute
Now with all that conceptual work done, we can get to the main topic of this post: Monte Carlo estimation. The basic idea behind Monte Carlo is to simulate the entire project (all 4 tasks in this case) a large number N (say 10,000) times and thus obtain N overall completion times. In each of the N trials, we simulate each of the tasks in the project and add them up appropriately to give us an overall project completion time for the trial. The resulting N overall completion times will all be different, ranging from the sum of the minimum completion times to the sum of the maximum completion times. In other words, we will obtain the PDF and CDF for the overall completion time, which will enable us to answer questions such as:
- How likely is it that the project will be completed within 17 days?
- What's the estimated time for which I can be 90% certain that the project will be completed? For brevity, I'll call this the 90% completion time in the rest of this piece.
"OK, that sounds great", you say, "but how exactly do we simulate a single task"?
Good question, and I was just about to get to that…
Simulating a single task using the CDF
As we saw earlier, the CDF for the triangular has a S shape and ranges from 0 to 1 in value. It turns out that the S shape is characteristic of all CDFs, regardless of the details underlying PDF. Why? Because, the cumulative probability must lie between 0 and 1 (remember, probabilities can never exceed 1, nor can they be negative).
OK, so to simulate a task, we:
- generate a random number between 0 and 1, this corresponds to the probability that the task will finish at time t.
- find the time, t, that this corresponds to this value of probability. This is the completion time for the task for this trial.
Incidentally, this method is called inverse transform sampling.
An example might help clarify how inverse transform sampling works. Assume that the random number generated is 0.4905. From the CDF for the first task, we see that this value of probability corresponds to a completion time of 4.503 days, which is the completion for this trial (see Figure 10). Simple!

Figure 10: Illustrating inverse transform sampling
In this case we found the time directly from the computed CDF. That's not too convenient when you're simulating the project 10,000 times. Instead, we need a programmable math expression that gives us the time corresponding to the probability directly. This can be obtained by solving equations (6) and (7) for

And
(t_{max} - t_{min})} \ldots\ldots(9)](https://eight2late.wordpress.com/2018/03/27/a-gentle-introduction-to-monte-carlo-simulation-for-project-managers/https://s0.wp.com/latex.php?latex=t+%3D+t_%7Bmax%7D+-+%5Csqrt%7B%5B1-P%28t%29%5D%28t_%7Bmax%7D+-%C2%A0+t_%7Bml%7D%29%28t_%7Bmax%7D+-+t_%7Bmin%7D%29%7D+%5Cldots%5Cldots%289%29&bg=ffffff&fg=1c1c1c&s=0&c=20201002)
These can be easily combined in a single Excel formula using an IF function, and I'll show you exactly how in a minute. Yes, we can now finally get down to the Excel simulation proper and you may want to download the workbook if you haven't done so already.
The simulation
Open up the workbook and focus on the first three columns of the first sheet to begin with. These simulate the first task in Figure 1, which also happens to be the task we have used to illustrate the construction of the triangular distribution as well as the mechanics of Monte Carlo.
Rows 2 to 4 in columns A and B list the min, most likely and max completion times while the same rows in column C list the probabilities associated with each of the times. For 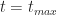
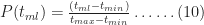
Rows 6 through 10005 in column A are simulated probabilities of completion for Task 1. These are obtained via the Excel RAND() function, which generates uniformly distributed random numbers lying between 0 and 1. This gives us a list of probabilities corresponding to 10,000 independent simulations of Task 1.
The 10,000 probabilities need to be translated into completion times for the task. This is done using equations (8) or (9) depending on whether the simulated probability is less or greater than 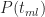
Tasks 2-4 are coded in exactly the same way, with distribution parameters in rows 2 through 4 and simulation details in rows 6 through 10005 in the columns listed below:
- Task 2 – probabilities in column D; times in column F
- Task 3 – probabilities in column H; times in column I
- Task 4 – probabilities in column K; times in column L
That's basically it for the simulation of individual tasks. Now let's see how to combine them.
For tasks in series (Tasks 1 and 2), we simply sum the completion times for each task to get the overall completion times for the two tasks. This is what's shown in rows 6 through 10005 of column G.
For tasks in parallel (Tasks 3 and 4), the overall completion time is the maximum of the completion times for the two tasks. This is computed and stored in rows 6 through 10005 of column N.
Finally, the overall project completion time for each simulation is then simply the sum of columns G and N (shown in column O)
Sheets 2 and 3 are plots of the probability and cumulative probability distributions for overall project completion times. I'll cover these in the next section.
Discussion – probabilities and estimates
The figure on Sheet 2 of the Excel workbook (reproduced in Figure 11 below) is the probability distribution function (PDF) of completion times. The x-axis shows the elapsed time in days and the y-axis the number of Monte Carlo trials that have a completion time that lie in the relevant time bin (of width 0.5 days). As an example, for the simulation shown in the Figure 11, there were 882 trials (out of 10,000) that had a completion time that lie between 16.25 and 16.75 days. Your numbers will vary, of course, but you should have a maximum in the 16 to 17 day range and a trial number that is reasonably close to the one I got.

Figure 11: Probability distribution of completion times (N=10,000)
I'll say a bit more about Figure 11 in the next section. For now, let's move on to Sheet 3 of workbook which shows the cumulative probability of completion by a particular day (Figure 12 below). The figure shows the cumulative probability function (CDF), which is the sum of all completion times from the earliest possible completion day to the particular day.

Figure 12: Probability of completion by a particular day (N=10,000)
To reiterate a point made earlier, the reason we work with the CDF rather than the PDF is that we are interested in knowing the probability of completion by a particular date (e.g. it is 90% likely that we will finish by April 20th) rather than the probability of completion on a particular date (e.g. there's a 10% chance we'll finish on April 17th). We can now answer the two questions we posed earlier. As a reminder, they are:
- How likely is it that the project will be completed within 17 days?
- What's the 90% likely completion time?
Both questions are easily answered by using the cumulative distribution chart on Sheet 3 (or Fig 12). Reading the relevant numbers from the chart, I see that:
- There's a 60% chance that the project will be completed in 17 days.
- The 90% likely completion time is 19.5 days.
How does the latter compare to the sum of the 90% likely completion times for the individual tasks? The 90% likely completion time for a given task can be calculated by solving Equation 9 for $t$, with appropriate values for the parameters
- Task 1 – 6.5 days
- Task 2 – 8.1 days
- Task 3 – 7.7 days
- Task 4 – 5.8 days
Summing up the first three tasks (remember, Tasks 3 and 4 are in parallel) we get a total of 22.3 days, which is clearly an overestimation. Now, with the benefit of having gone through the simulation, it is easy to see that the sum of 90% likely completion times for individual tasks does not equal the 90% likely completion time for the sum of the relevant individual tasks – the first three tasks in this particular case. Why? Essentially because a Monte Carlo run in which the first three tasks tasks take as long as their (individual) 90% likely completion times is highly unlikely. Exercise: use the worksheet to estimate how likely this is.
There's much more that can be learnt from the CDF. For example, it also tells us that the greatest uncertainty in the estimate is in the 5 day period from ~14 to 19 days because that's the region in which the probability changes most rapidly as a function of elapsed time. Of course, the exact numbers are dependent on the assumed form of the distribution. I'll say more about this in the final section.
To close this section, I'd like to reprise a point I mentioned earlier: that uncertainty is a shape, not a number. Monte Carlo simulations make the uncertainty in estimates explicit and can help you frame your estimates in the language of probability…and using a tool like Excel can help you explain these to non-technical people like your manager.
Closing remarks
We've covered a fair bit of ground: starting from general observations about how long a task takes, saw how to construct simple probability distributions and then combine these using Monte Carlo simulation. Before I close, there are a few general points I should mention for completeness…and as warning.
First up, it should be clear that the estimates one obtains from a simulation depend critically on the form and parameters of the distribution used. The parameters are essentially an empirical matter; they should be determined using historical data. The form of the function, is another matter altogether: as pointed out in an earlier section, one cannot determine the shape of a function from a finite number of data points. Instead, one has to focus on the properties that are important. For example, is there a small but finite chance that a task can take an unreasonably long time? If so, you may want to use a lognormal distribution…but remember, you will need to find a sensible way to estimate the distribution parameters from your historical data.
Second, you may have noted from the probability distribution curve (Figure 11) that despite the skewed distributions of the individual tasks, the distribution of the overall completion time is somewhat symmetric with a minimum of ~9 days, most likely time of ~16 days and maximum of 24 days. It turns out that this is a general property of distributions that are generated by adding a large number of independent probabilistic variables. As the number of variables increases, the overall distribution will tend to the ubiquitous Normal distribution.
The assumption of independence merits a closer look. In the case it hand, it implies that the completion times for each task are independent of each other. As most project managers will know from experience, this is rarely the case: in real life, a task that is delayed will usually have knock-on effects on subsequent tasks. One can easily incorporate such dependencies in a Monte Carlo simulation. A formal way to do this is to introduce a non-zero correlation coefficient between tasks as I have done here. A simpler and more realistic approach is to introduce conditional inter-task dependencies As an example, one could have an inter-task delay that kicks in only if the predecessor task takes more than 80% of its maximum time.
Thirdly, you may have wondered why I used 10,000 trials: why not 100, or 1000 or 20,000. This has to do with the tricky issue of convergence. In a nutshell, the estimates we obtain should not depend on the number of trials used. Why? Because if they did, they'd be meaningless.
Operationally, convergence means that any predicted quantity based on aggregates should not vary with number of trials. So, if our Monte Carlo simulation has converged, our prediction of 19.5 days for the 90% likely completion time should not change substantially if I increase the number of trials from ten to twenty thousand. I did this and obtained almost the same value of 19.5 days. The average and median completion times (shown in cell Q3 and Q4 of Sheet 1) also remained much the same (16.8 days). If you wish to repeat the calculation, be sure to change the formulas on all three sheets appropriately. I was lazy and hardcoded the number of trials. Sorry!
Finally, I should mention that simulations can be usefully performed at a higher level than individual tasks. In their highly-readable book, Waltzing With Bears: Managing Risk on Software Projects, Tom De Marco and Timothy Lister show how Monte Carlo methods can be used for variables such as velocity, time, cost etc. at the project level as opposed to the task level. I believe it is better to perform simulations at the lowest possible level, the main reason being that it is easier, and less error-prone, to estimate individual tasks than entire projects. Nevertheless, high level simulations can be very useful if one has reliable data to base these on.
There are a few more things I could say about the usefulness of the generated distribution functions and Monte Carlo in general, but they are best relegated to a future article. This one is much too long already and I think I've tested your patience enough. Thanks so much for reading, I really do appreciate it and hope that you found it useful.
Acknowledgement: My thanks to Peter Holberton for pointing out a few typographical and coding errors in an earlier version of this article. These have now been fixed. I'd be grateful if readers could bring any errors they find to my attention.
Source: https://eight2late.wordpress.com/2018/03/27/a-gentle-introduction-to-monte-carlo-simulation-for-project-managers/
Posted by: deanmammengae0194761.blogspot.com

Post a Comment for "Monte Carlo Simulation Construction Projects"